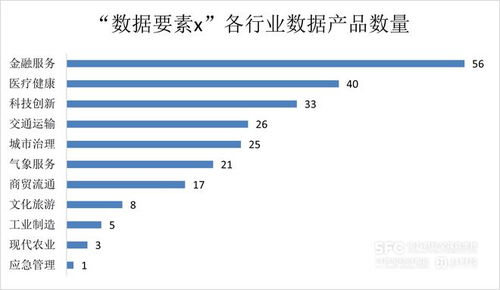
哔哩哔哩数据服务中台建设实践 构建高效、可靠的数据处理服务
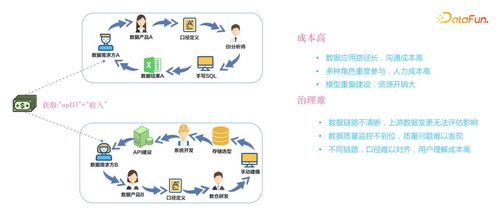
在数字化浪潮中,数据已成为企业决策与业务增长的核心驱动力。对于哔哩哔哩这样拥有海量用户、丰富内容生态和复杂业务场景的年轻文化社区,如何高效、可靠地管理和利用数据,是其持续创新的关键。为此,哔哩哔哩近年来着力推进数据服务中台建设,特别是其核心组成部分——数据处理服务的体系化构建。本文将探讨哔哩哔哩在这一领域的实践路径与核心洞察。
一、 建设背景与核心挑战
哔哩哔哩的业务涵盖视频、直播、游戏、漫画、电商等多个板块,每日产生PB级别的数据。在传统模式下,数据处理往往呈现“烟囱式”架构:各业务线独立开发数据管道,导致计算资源浪费、数据口径不一、运维成本高昂,且难以快速响应跨业务的数据分析需求。因此,构建统一、标准化、服务化的数据处理中台,实现数据的“采、建、管、用”一体化,成为必然选择。
二、 数据处理服务的核心架构
哔哩哔哩的数据处理服务中台旨在提供从数据接入、加工、存储到服务化输出的全链路能力。其核心架构通常分为三层:
- 统一接入与调度层:整合Kafka、Flume等多种数据源,通过统一的元数据管理和任务调度系统(如基于Airflow或自研调度平台),实现数据采集与处理任务的自动化、可视化编排。这确保了数据入口的规范性和任务执行的可靠性。
- 核心计算与存储层:这是数据处理服务的“引擎”。哔哩哔哩大规模采用Apache Flink进行实时流处理,以应对弹幕、互动、播放等实时性要求高的场景;利用Apache Spark、Hive等进行海量数据的离线批量计算与历史分析。存储方面,结合HDFS、HBase、ClickHouse、OLAP数据库及对象存储,形成分层、多模的存储体系,兼顾成本与性能。
- 统一服务与治理层:通过数据仓库(DW)和数据湖(Data Lake)的融合架构,对清洗、加工后的数据进行主题域建模,形成一致、可信的数据资产。并在此基础上,提供统一的数据查询服务、API服务以及数据质量监控、血缘追踪、安全权限管理等治理工具,让业务方能够像使用“水电煤”一样便捷、安全地消费数据。
三、 关键实践与技术创新
- 流批一体化的探索:为了简化架构、保证数据处理逻辑的一致性,哔哩哔哩积极探索流批一体技术。通过Flink的批流统一引擎,部分场景下实现了同一套代码既可处理实时流数据,也可处理历史批量数据,显著提升了开发效率与运维便利性。
- 数据质量与可信保障:建立了贯穿全链路的数据质量监控体系。在任务调度层面设置强弱依赖报警;在数据层面,对关键指标设置完整性、准确性、及时性校验规则;并通过数据血缘分析,快速定位数据异常的影响范围,确保输出数据的可信度。
- 资源优化与成本控制:面对巨大的计算规模,通过细粒度的资源池化管理、计算任务智能调优(如自动识别可合并的小文件、动态调整计算资源)、冷热数据分级存储等策略,在保障SLA(服务等级协议)的有效降低了整体基础设施成本。
- 自助化与体验提升:为业务研发和数据分析师提供可视化的数据开发平台、即席查询工具和指标管理平台。用户可以通过拖拽配置或简单SQL完成数据任务的开发与发布,极大降低了数据使用的技术门槛,加速了数据价值释放的进程。
四、 价值与未来展望
通过数据处理服务中台的建设,哔哩哔哩实现了:数据开发效率提升、资源利用率优化、数据质量与一致性保障,以及跨业务数据协作能力的增强。这使得推荐算法、内容运营、商业变现、用户体验优化等关键业务能够更快、更准地基于数据做出决策。
随着AIGC、元宇宙等新趋势的发展,数据规模与复杂性将持续攀升。哔哩哔哩的数据处理服务将继续向更智能、更实时、更易用的方向演进:例如,深化实时数仓建设,实现更细粒度的实时决策;探索数据湖仓一体化的更优解;并可能引入AI能力进行智能运维、自动优化与数据洞察,最终构建一个能够充分激发社区活力、赋能内容生态的智能数据基础设施。
如若转载,请注明出处:http://www.unicodema.com/product/4.html
更新时间:2026-06-19 16:17:27